分数排名函数公式全解析:从基础逻辑到高级应用
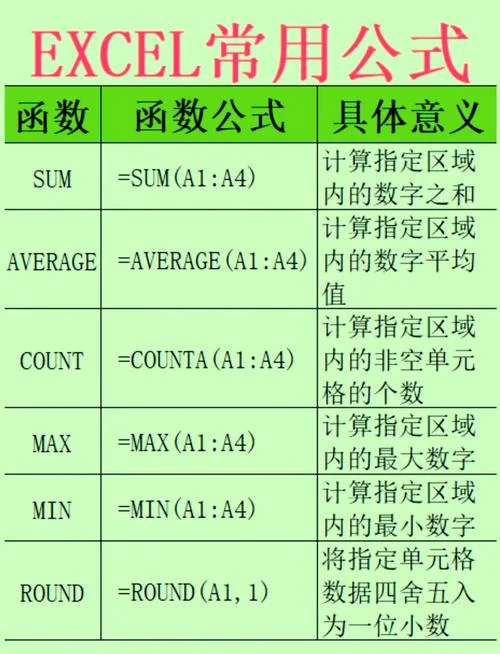
在数据分析、财务建模、人力资源评估以及学术统计等场景中,“分数排名函数”(Ranking Function)是决定结果公平性与决策准确性工具。无论是决定谁能晋升、谁获得奖金,还是计算比赛名次,精准高效的排名公式都能为组织提供强有力的数据支撑。这篇文章将深入探讨各类主流排名函数的逻辑、适用场景及实战技巧,并辅以数据说明表格。
核心概念:什么是排名函数?
与简单的“平均值”或“和”不同,排名函数关注的是相对顺序。即:将一组数值从小到大排序,并赋予每个数值一个位置索引(从 1 开始)。
升序:数值越小,排名越靠前(如:1 号、2 号、3 号)。
降序:数值越大,排名越靠前(如:1 号、2 号、3 号)。
常见的排名函数包括 `RANK()`、`ROW_NUMBER()`、`DENSE_RANK()` 和 `PERCENT_RANK()`。
主流排名函数详解与对比
在实际应用中,不同的函数各有侧重。以下通过表格直观对比其核心逻辑、适用场景及优缺点。
RANK 函数 (旧版通用版)
| 特性 | 说明 |
|---|---|
| 逻辑 | 当排名值相,所有并列的数值共享这个排名号。 |
| 结果示例 | 数据:[90, 90, 85, 85] |
| 排名结果 | 90 分有两位排名,均为第 1 名;85 分有两位排名,均为第 3 名。 |
| 代码/语法 | `RANK(Col1, [Col2], [Order])` |
| 适用场景 | 需明确并列情况,且并列者之间排名一致的场景(如奥运奖牌:金牌、银牌、铜牌并列时)。 |
| 缺点 | 排名号包含重复数字(如两个并列第 1 名),视觉上不如连续数字直观。 |
ROW_NUMBER() (数据库专用版)
| 特性 | 说明 |
|---|---|
| 逻辑 | 为每一行数据分配唯一的连续整数(1, 2, 3...),即使有重复值也不会重复。 |
| 结果示例 | 数据:[90, 90, 85, 85] |
| 排名结果 | 90 分分别获得第 1 名和第 2 名;85 分分别获得第 3 名和第 4 名。 |
| 代码/语法 | `ROW_NUMBER() OVER (ORDER BY ...)` (SQL 语法) |
| 适用场景 | 需要区分同一组数据的不同个体,用于统计每个具体个体的相对位置(如员工绩效中员工 A 与员工 B 虽同分,但需区分两人)。 |
| 缺点 | 排名号不连续,且无法直接获取“并列组”的统计信息。 |
DENSE_RANK() (连续版)
| 特性 | 说明 |
|---|---|
| 逻辑 | 当排名值相,保持连续的排名号,中间无空缺。 |
| 结果示例 | 数据:[90, 90, 85, 85] |
| 排名结果 | 90 分有两位排名,均为第 1 名;85 分有两位排名,均为第 2 名。 |
| 代码/语法 | `DENSE_RANK() OVER (ORDER BY ...)` |
| 适用场景 | 大多数业务场景的通用选择,既保证了连续排名,又明确了并列关系。 |
| 缺点 | 同样,排名号内部也包含重复数字。 |
PERCENT_RANK() (百分位版)
| 特性 | 说明 |
|---|---|
| 逻辑 | 返回当前值在排序后的位置百分比( 0.15 显示该值排在第 15% 的位置)。 |
| 结果示例 | 数据:[90, 90, 85, 85] |
| 排名结果 | 90 分分别位于 83.3% 和 86.7%;85 分分别位于 66.7% 和 73.3%。 |
| 代码/语法 | `PERCENT_RANK() OVER (ORDER BY ...)` |
| 适用场景 | 需要直观展示数据在分布中的相对位置,而不关心具体的绝对排名号。常用于技能评估或分数线段划分。 |
| 缺点 | 无法用于对等的排名比较(如比较谁排第 1 名,因为那是百分比,不是绝对名次)。 |
实战数据说明

为了更清晰地展示不同函数的表现差异,以下凭借模拟薪资评估案例进行数据说明。
案例背景:某公司年度员工绩效评估
假设我们需要计算每位员工的平均薪资,并生成排名。
| 员工编号 | 平均薪资 (元) | RANK() 函数结果 | ROW_NUMBER() 函数结果 | DENSE_RANK() 函数结果 | 说明 |
|---|---|---|---|---|---|
| 员工 A | 5000 | 1 | 1 | 1 | 并列第 1 名,RANK 无重复 |
| 员工 B | 5000 | 2 | 2 | 2 | 并列第 1 名,RANK 有重复 |
| 员工 C | 5500 | 3 | 3 | 3 | 并列第 2 名,RANK 有重复 |
| 员工 D | 6000 | 4 | 4 | 4 | 新的高分 |
| 员工 E | 6000 | 5 | 5 | 5 | 并列第 3 名,RANK 有重复 |
对比分析:
如果员工 C 薪资 10000,而员工 E 薪资 9000。
RANK(): 员工 C 为第 1 名,员工 E 为第 2 名。
ROW_NUMBER(): 员工 C 为第 2 名,员工 E 为第 3 名。
DENSE_RANK(): 员工 C 为第 1 名,员工 E 为第 2 名。
关键数据洞察:
在绩效管理中,推荐使用 `DENSE_RANK()`。由于员工 C 和员工 E 虽然薪资不同,但作为竞争对手,他们处于同一竞争梯队(并列第 2 名),`DENSE_RANK()` 更能体现这种竞争关系的紧密度,避免 `ROW_NUMBER()` 带来的细微差别干扰决策。
综合应用场景与选择建议
奖金分配与晋升
需求:基于绝对分数高低决定奖惩。 推荐:`DENSE_RANK()`。 理由:确保高分者获得更高奖励,避免分数微小差异导致的排名剧烈震荡。比赛名次统计
需求:需要清晰展示“第几名”的概念,并列者需明确。 推荐:根据具体编程语言或数据库选择。 Excel/Google Sheets: 使用 `RANK` 或 `ROW_NUMBER()` 结合公式。 SQL: 运用 `ROW_NUMBER()` 配合 `WHERE Rank = 1` 查询冠军,或 `DENSE_RANK()` 配合 `WHERE DENSE_RANK <= 1` 查询冠军组。技能等级划分 (如:S/A/B/C 等级)
需求:将分数区间划分为等级,且等级之间无重叠。 推荐:自定义逻辑(如 `CASE WHEN`)。 逻辑: 100-120 分 -> S 级 80-99 分 -> A 级 60-79 分 -> B 级 <60 分 -> C 级 (注:此场景极少利用标准排名函数,建议使用分段函数)技能掌握程度评估 (百分位)
需求:展示学员相对于全班平均水平的掌握进度。 推荐:`PERCENT_RANK()`。 理由:直观反映进度(:95% 的学员已掌握,代表该学员是班级中水平最高的 95%)。常见错误规避
在使用排名函数时,常出现以下误区:
1. 忽略了排序依据:`RANK()` 默认按升序,若数据需降序排名,必须指定 `ORDER BY col DESC`。
2. 未处理空值:如果某列包含 NULL,某些函数会报错。需确保在排序前处理空值(如使用 `COALESCE` 填充默认值,或采用 `ISNULL`)。
3. 重复值处理不当:若希望重复值之间排名不同,必须运用 `ROW_NUMBER()`,而不要误用 `RANK()`。
4. 性能问题:在大数据量(>10 万行)查询中,窗口函数(Window Functions)较慢。务必先对数据进行排序(`ORDER BY`),再进行 `RANK()` 计算,以最大化 SQL 引擎性能。
掌握分数排名函数的公式,不仅是为了写出正确的代码,更是为了理解数据背后的竞争逻辑。
若需绝对名次且看重并列,选 RANK;
若需连续排名且看重竞争梯队,选 DENSE_RANK;
若需相对位置或百分比,选 PERCENT_RANK。
结合真实业务场景选择合适的函数,是构建高质量数据模型的步。希望这篇文章提供的解析与数据表格能为您的数据分析工作提供有力支持。














